Introdução
Qual a capacidade de processamento da retaguarda NFCe versão 4.8.5 e 4.8.6?
Passo a passo
Recentemente surgiu a necessidade de sabermos o poder de processamento do nosso Job NFCe. Para isso realizamos testes de carga com o seguinte ambiente.
Servidor utilizado foi uma máquina física com a seguinte especificação:
Processador: Intel Core i5-6600 CPU @3.30GHz (4CPUs);
Memória: 16,0GB;
Sistema Operacional: Windows Server 2012 R2 Standard;
Banco de Dados: Microsoft SQL Server 2012 R2 Enterprise.
Para medirmos a quantidade de documentos processados pelo Eletronic foi parado o serviço DatabaseInput, processados 30.000 documentos com 50 itens cada em contingência represando na tabela TBDATABASEINPUT. Ao iniciar o serviço DatabaseInput foi medido o tempo de consumo total da tabela TBDATABASEINPUT, o tempo total de processamento da tabela TBINPROCESS e por fim o tempo que todos os documentos foram inseridos no Cold nos seguintes cenários:
Teste 01: 1 Job 10 Docs por Lote, 1 Executor e 1 Instância;
Teste 02: 2 Jobs 10 Docs por Lote, 1 Executor e 1 Instância;
Teste 03: 2 Jobs 10 Docs por Lote, 2 Executores e 1 Instância;
Teste 04: 2 Jobs 10 Docs por Lote, 2 Executores e 2 Instâncias.
Segue os Resultados:
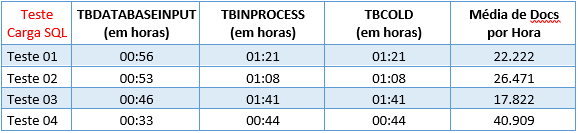
A versão utilizada para os testes foi a 4.8.5.
Para mantermos o tempo de inserção das notas do Cold próximo ao do processamento da TBINPROCESS, foi alterado o parâmetro CommitBlock de 100 para 1 no regedit do Cold.
Considerações:
1 - Referente a quantidade de Docs por lote, foi refeito o Teste 01 utilizando 50 Docs por Lote e o resultado foi praticamente o mesmo (22.222 Docs por hora) ou seja, o sistema leva o mesmo tempo para montar 5 lotes de 10 Docs ou 1 lote de 50 Docs;
Obs: Caso a Sefaz esteja com um tempo de resposta grande, é melhor que menos comunicações com ela sejam realizadas, sendo assim é aconselhável que utilize-se o valor de 50 Docs por lote, para comunicar menos vezes com o WS da Sefaz.
2 - Referente aos Logs, no Teste 04 foi comentada as linhas de Logs dos dois Serviços do Eletronic e do DatabaseInput não gerando registros de logs a fim de verificar se a escrita de logs interfere no tempo de processamento e o resultado foi exatamente o mesmo (40.909 Docs por hora) mostrando que nossos logs estão bem otimizados;
3 - Referente aos testes em Banco Oracle, fizemos o Teste 01 utilizando a versão 11g e o resultado foi cerca de 20% mais lento que no SQL:

Acreditamos que isso pode ocorrer pois nos nossos ambientes de testes utilizamos o Server do Oracle em Windows e que dificilmente iremos encontrar clientes que utilizam este cenário, ou seja, enquanto não montarmos um server Oracle em Linux, os testes de carga em Oracle não serão válidos.
Não é apenas a nossa Solução que tem o processo um pouco mais lento no Oracle, em conversa com o Spanhol, o mesmo relatou que o NFSe, que utiliza o mesmo cenário em ambiente Oracle, também fica mais lento.
4 - Manipulando as Threads. Na versão 4.8.6 o Lucas realizou uma implementação para manipularmos a quantidade de threads por executor (os valores abaixo são o padrão da solução):
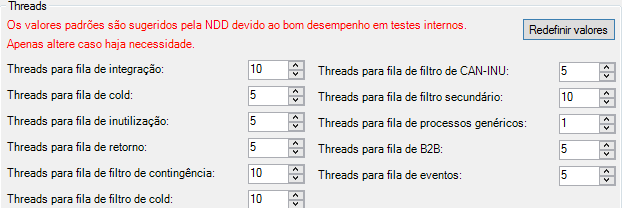
Obs: Somente o usuário nddmaster terá acesso para alteração das Threads.
Foram refeitos o Testes 01, sem mexer na quantidade de threads para vermos se tínhamos diferenças de da versão 4.8.5 e 4.8.6, e o Teste 02 aumentando a “Threads para fila de retorno” para 10, a “Threads para fila de cold” para 10 e diminuído a “Threads para fila de integração” para 7. Segue o resultado:

Com esse resultado concluímos que não adianta aumentarmos a quantidade de Threads se o processador não dá conta de utiliza-las, gerando assim um possível gargalo.
Refizemos novamente todos os testes na versão 4.8.6, porém dessa vez, diminuindo pela metade a quantidade das Threads:

Segue os resultados:

Com esse resultado, podemos observar um ganho ao diminuir as Thread com o nosso modelo de processador.
Conclusão:
Em um Servidor com desempenho mediano, nossa solução conseguiu processar cerca de 40 mil documentos por hora quando configurada corretamente e com a quantidade de threads padrões e isso supre a demanda de nossos maiores Clientes, sem a necessidade de novas alterações de performance, tendo em vista que terão servidores ainda mais potentes. Nosso i5 de 6ª geração se tornou um gargalo, ficando uma grande parte do tempo acima dos 95% de uso chegando a picos de 100%, como mostra a imagem abaixo, e com processadores melhores o resultado será ainda melhor.
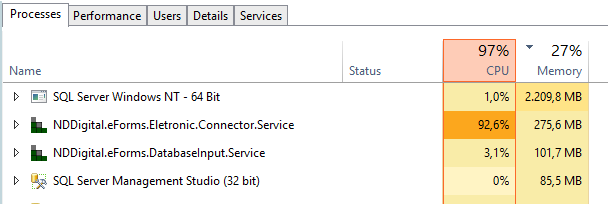
A manipulação das Threads deve ser estudada com mais calma, pois apesar de termos um desempenho significativo diminuindo a quantidade, o resultado pode variar dependendo do tipo de processador que está sendo usado e isso no momento não podemos medir pois não temos um processador melhor que o i5 de 6 geração em uma máquina física.
Outras informações
Fonte: Rainmakers Team